体育游戏app平台它不径直输出单一动作-开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口
发布日期:2026-02-14 07:15 点击次数:147

IT之家 2 月 12 日音书,小米本日对外发布开源 VLA 模子 Xiaomi-Robotics-0体育游戏app平台,领有 47 亿参数、兼具视觉话语认知与高性能及时实践才智,刷新多项 SOTA。它不仅在三大主流的仿真测试中得回优异获利,更在践诺真机任务中竣事了物沉默能的泛化 —— 动作连贯、反应贤人,且能在消耗级显卡上竣事及时推理。

IT之家从官方先容获悉,物沉默能的中枢在于“感知-决议-实践”的闭环质地。为了兼顾通用认知与细巧抑止,Xiaomi-Robotics-0 遴荐了主流的 Mixture-of-Transformers (MoT) 架构。
视觉话语大脑(VLM): 团队遴荐了多模态 VLM 大模子看成底座。它认真认知东说念主类的微辞提醒(如“请把毛巾叠好”),并从高清视觉输入中捕捉空间联系。
动作实践小脑(Action Expert):为了生成高频、平滑的动作,团队镶嵌了多层的 Diffusion Transformer (DiT)。它不径直输出单一动作,而是生成一个“动作块”(Action Chunk),并通过流匹配(Flow-matching)时候确保动作的精确度。
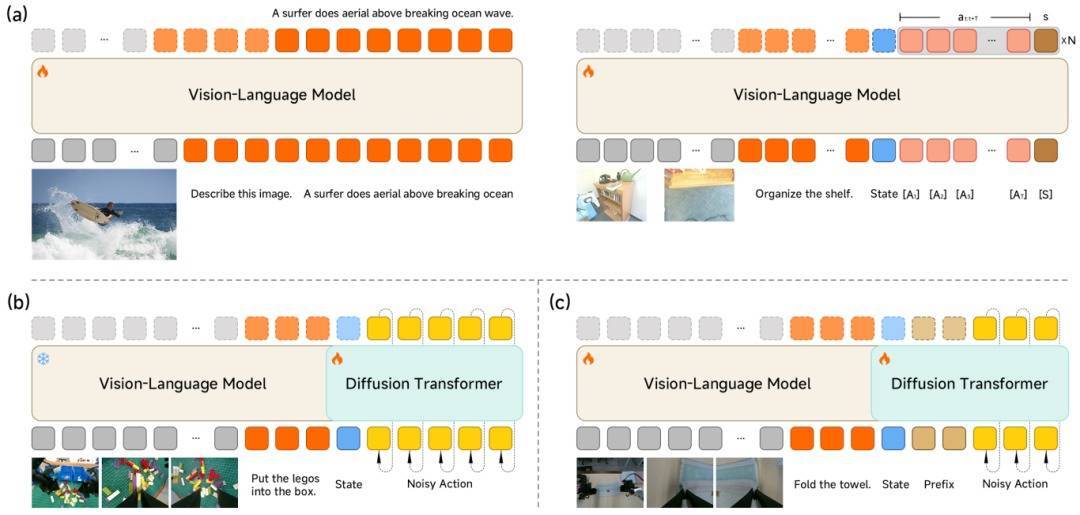
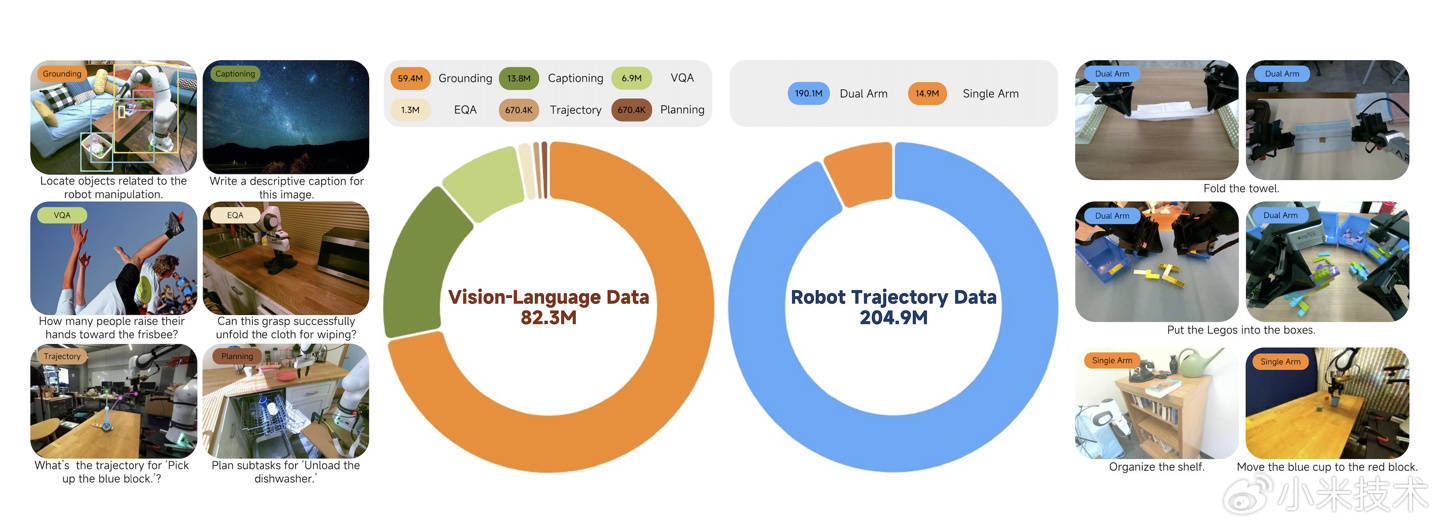
大部分 VLA 模子在学动作时雷同会“变笨”,失去本人的认知才智。咱们通过多模态与动作数据的夹杂检会,让模子在学会操作的同期,如故保合手浩大的物体检测、视觉问答和逻辑推理才智。
VLM 协同检会:当先引入了 Action Proposal 机制,免强 VLM 模子在认知图像的同期瞻望多种动作漫衍。这一步是为了让 VLM 的特征空间与动作空间对王人,不再只是是“画饼果腹”。
DiT 专项检会:随后冻结 VLM,专注于检会 DiT,学习如何从噪声中还原出精确的动作序列。这一阶段,咱们去除了 VLM 的冲破 Token,饱和依赖 KV 特征进行条目生成。通过 DiT 专项检会,模子不错生成高度平滑、精确的的动作序列。
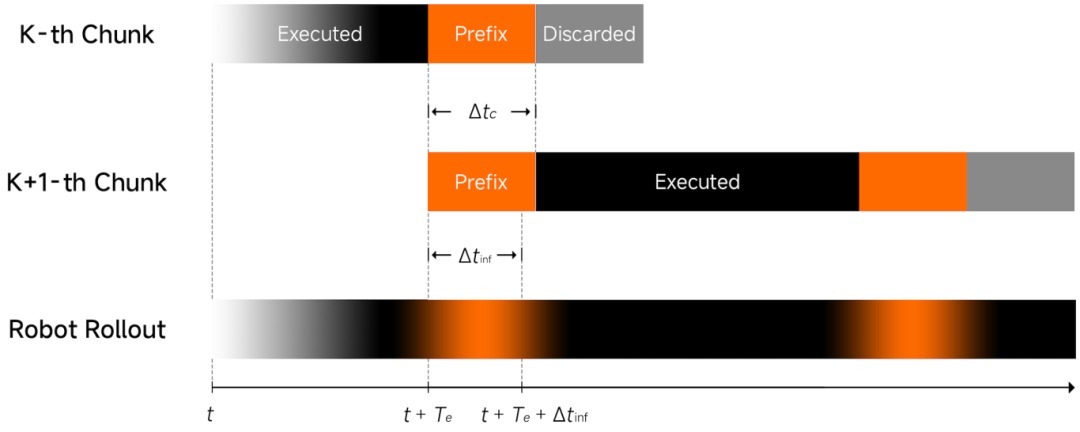
针对推理延长激发的真机“动作断层”问题,团队遴荐异步推理形式 —— 让模子推理与机器东说念主开动脱离同步不休、异步实践,从机制上保险动作连清醒畅。为进一步强化模子对环境变化的反应敏捷性与开动踏实性,咱们引入了:
Clean Action Prefix:将前一时刻瞻望的动作看成输入,确保动作轨迹在时间维度上是聚首的、不抖动的,进一步加多绽开性。
Λ-shape Attention Mask:通过突出的详实力掩码,强制模子更关心现时的视觉反馈,而不是千里溺于历史惯性。这让机器东说念主在面临环境突发变化时,好像展现出极强的反应性物沉默能。

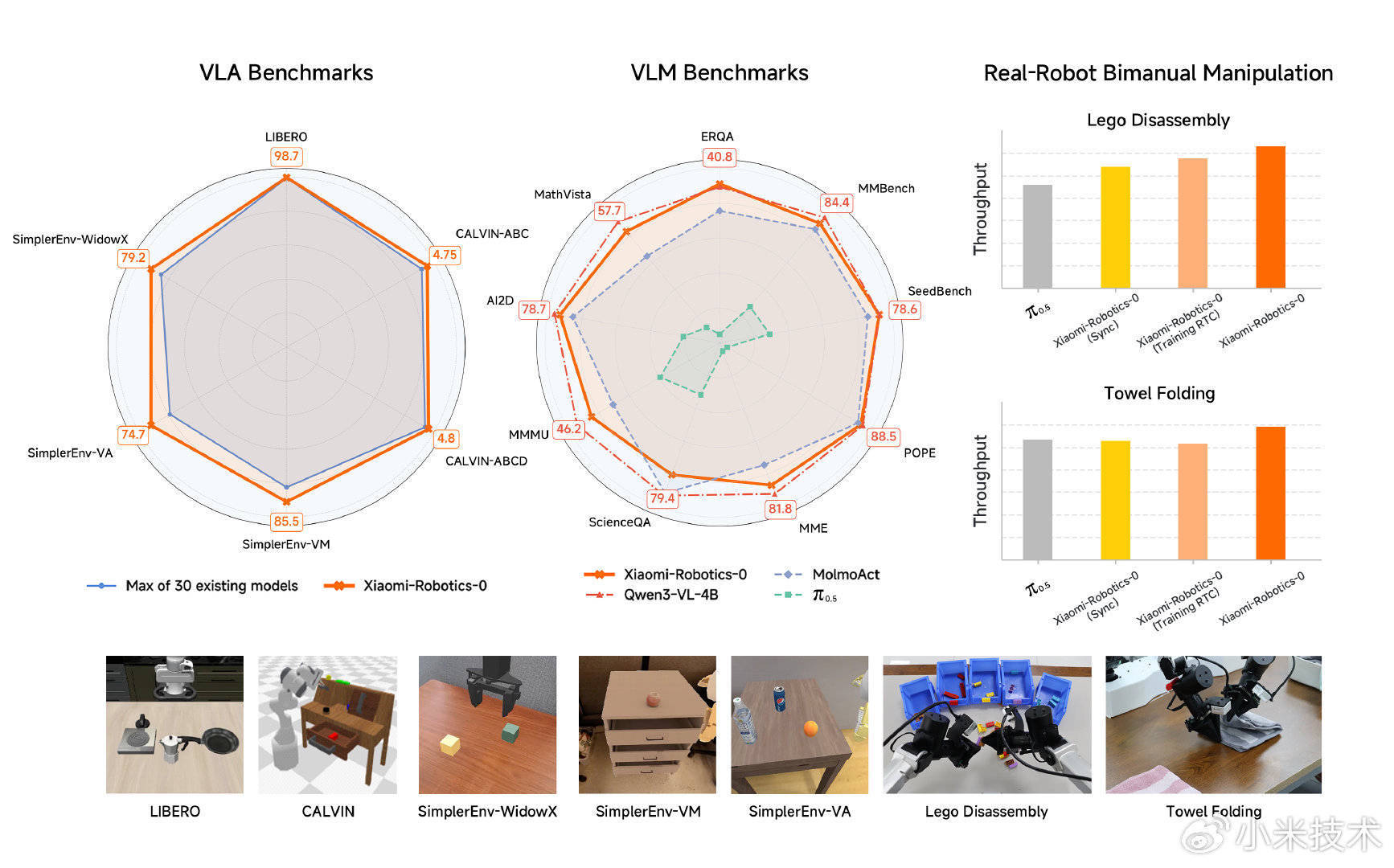
在多维度的测试中,Xiaomi-Robotics-0 展现出优异的进展:
仿真标杆: 在 LIBERO、CALVIN 和 SimplerEnv 测试中,模子在总共的 Benchmark、30 种模子对比中,均取得了现时最优的收尾。
真确挑战: 团队在双臂机器东说念主平台上部署了模子并与行业标杆进行了横向对比。在积木拆解和叠毛巾这种长周期、高度挑战的任务中,机器东说念主展现出了极高的手眼协作性。不论是刚性的积木照旧柔性的织物,都能处置得洋洋纚纚。
多模态才智:模子保留了 VLM 本人的多模态认知才智,尤其是在具身更磋议的 benchmark 中进展优异,这是之前的 VLA 模子所不具备的。
小米文书将模子进行开源:
时候主页:https://xiaomi-robotics-0.github.io
开源代码:https://github.com/XiaomiRobotics/Xiaomi-Robotics-0
模子权重:https://huggingface.co/XiaomiRobotics体育游戏app平台
Powered by 开云官网kaiyun皇马赞助商 (中国)官方网站 登录入口 @2013-2022 RSS地图 HTML地图